当前,人们的生活越来越离不开社交平台(如微信,微博等),图片分享占据社交平台的主要内容。然而,图片在捕获、后处理、存储与传输过程中总会引入或多或少的失真。如何利用人工智能算法自动化评价一幅图像的质量(Image Quality Assessment,IQA),使得评价结果与人的主观观感尽可能一致是一项有现实意义的研究课题。
问题背景:
深度学习依靠带标注的样本数据进行训练,可获得精度较高的模式分类与识别结果。由于人工标注模式的类别相对容易,各种大型的带标签的数据集(千万数量级)纷纷发展起来提升深度学习模型的性能。然而,人工评价一幅图像的质量却需要在非常严格的实验环境下进行,并需要雇用大量的不同年龄不同职业的人来进行主观打分,从而获得一个广泛接受的平均分(Mean Opinion Score, MOS)。这需要消耗大量的人力成本,导致当前的IQA数据集都比较小(1000数量级),这不足于训练性能优良的深度网络。
国际学者提出采取多个不同等级人工合成失真标签图片的方法,尽管这些人工合成失真的图片没有MOS分,但是他们的质量排序信息是已知的,因此可以利用排序学习算法预训练网络,再利用IQA数据集微调预训练过的网络,从而提高了IQA网络模型的性能。然而,当前排序学习算法只考虑了排序的正确性,却忽略了排序预训练时网络输出分数的不可控性,导致预训练性能提升受限。此外,当前的排序学习不适用于自然的真实失真的IQA数据集。因为,自然失真非常复杂,很难建模。
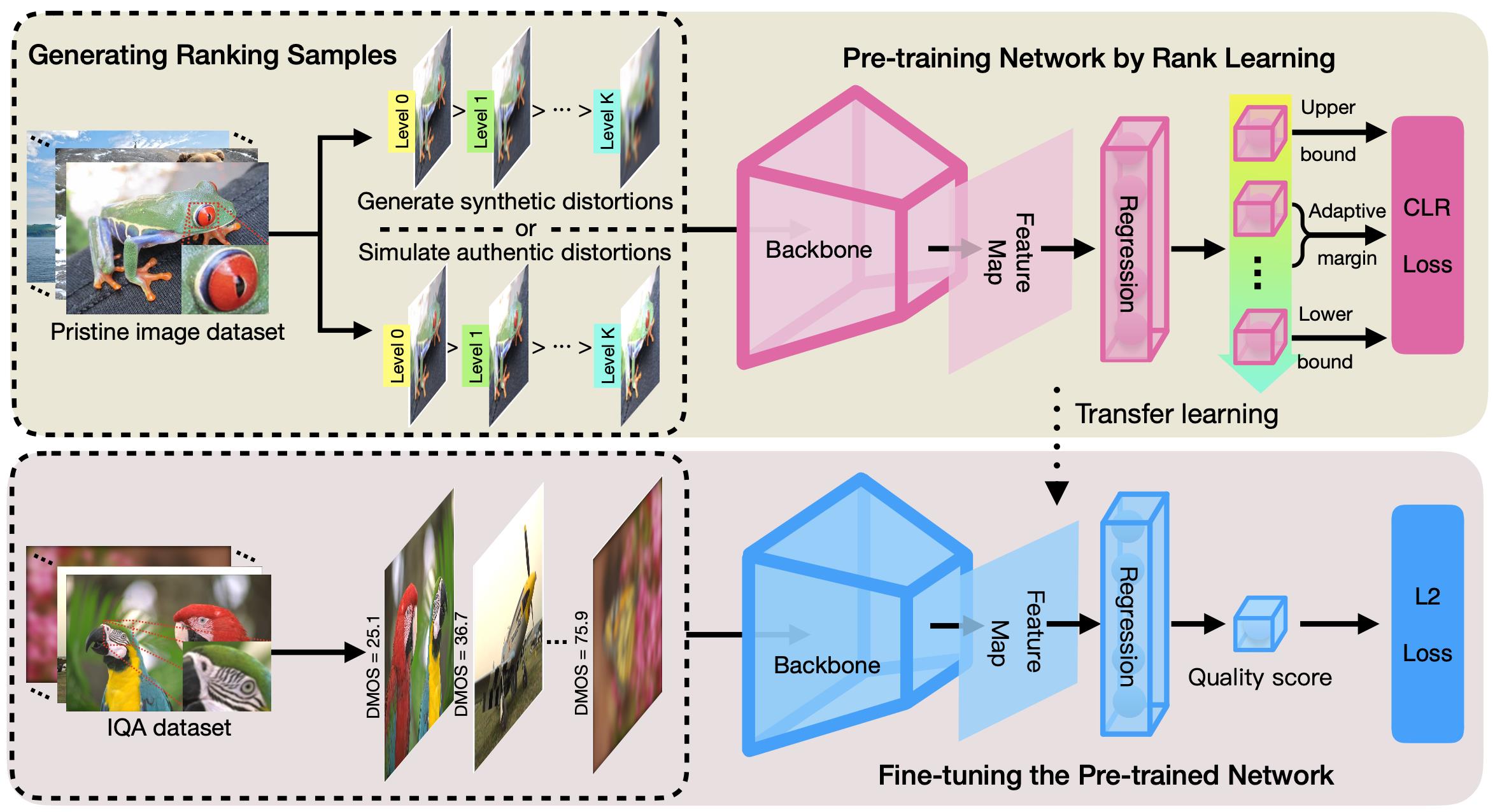
图1.算法CLRIQA框图
研究内容:
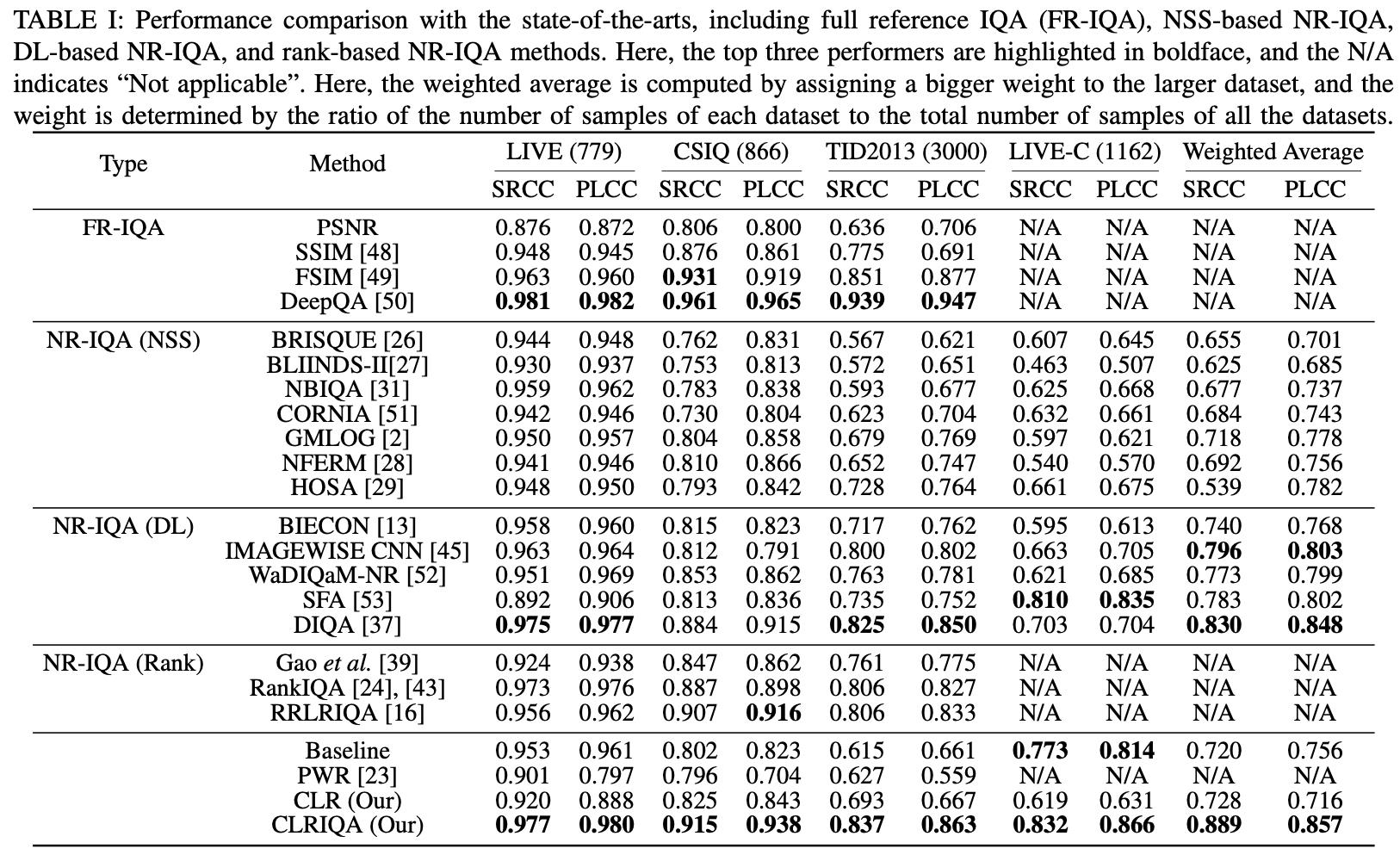
受上述两大问题驱动,本文提出了一种可控列排序学习的IQA算法(Controllable List-Wise Ranking IQA, CLRIQA),它包括CLR损失函数和成像启发式方法(Imaging-Heuristic Approach, IHA)。1)CLR使得排序学习预训练不仅排序正确,且输出的分数不会失控,即与输入的失真排序样本的质量基本一致,这极大提升了排序预训练的精度;2)IHA模拟真实失真,从而可获得真实失真图像的多个级别的失真样本。结果,排序学习方法也适用于真实失真的IQA数据集。事实上,评价自然的真实失真图像的质量更符合现实应用。本文算法框图如图1所示,它包括生成排序样本模块,预训练模块和微调模块。我们实验对比了当前国际主流的20种IQA方法,总体性能如表1所示。由表1可得,我们的方法性能SOTA。
论文第一作者为硕士研究生区富炤,其指导教师王员根教授为该论文的唯一通讯作者,广州大学为第一署名单位,合作单位有哈尔滨工业大学和香港城市大学。
论文信息:Fu-Zhao Ou,Yuan-Gen Wang*,Jin Li, Guopu Zhu, and Sam Kwong, A novel rank learning based no-reference image quality assessment method,IEEE Transactions on Multimedia, pp.1-15, 2021. DOI: 10.1109/TMM.2021.3114551.
论文链接:https://ieeexplore.ieee.org/document/9548827.
算法源码:https://github.com/GZHU-DVL/CLRIQA.

